utf-8 - codifica dei caratteri
Unicode supporta quasi tutti gli esistentiset di caratteri. La migliore forma di codifica dei set di caratteri Unicode è la codifica utf-8. Fornisce compatibilità con ASCII, resistenza al danneggiamento dei dati, efficienza e facilità di elaborazione. Ma su tutto in ordine.
Forme di codifica
I computer operano con numeri non solo comeoggetti astratti matematici, nonché le combinazioni di unità di stoccaggio e di dati di dimensione fissa movimentazione - byte e 32 bit parole. Lo standard di codifica deve tenerne conto nel determinare il modo in cui i caratteri sono rappresentati da numeri.
Nei sistemi informatici, gli interi sono archiviati incelle di memoria della dimensione di 8 bit (1 byte), 16 o 32 bit. Ogni modulo di codifica Unicode determina quale sequenza di celle di memoria rappresenta un intero corrispondente a un particolare carattere. Lo standard fornisce tre diverse forme di codifica di caratteri Unicode: blocchi da 8, 16 e 32 bit. Di conseguenza, sono chiamati utf-8, UTF-16 e UTF-32. Il nome UTF sta per formato di conversione Unicode. Ciascuna delle tre forme di codifica è un mezzo equivalente per rappresentare i caratteri Unicode, presenta vantaggi in varie applicazioni.
Queste codifiche possono essere utilizzate perrappresentazione di tutti i caratteri Unicode. Pertanto, sono completamente compatibili per soluzioni per diversi motivi che utilizzano diverse forme di codifica. Ogni codifica può essere convertita in modo univoco in uno qualsiasi degli altri due senza perdita di dati.

Principio di non-imposizione
Ciascuno dei moduli di codifica Unicode è progettato contenendo conto dell'ammissibilità delle sovrapposizioni parziali. Ad esempio, Windows-932 genera caratteri da uno o due byte di codice. La lunghezza della sequenza dipende dal primo byte, quindi i valori del byte iniziale nella sequenza di due byte e un singolo byte non si intersecano. Tuttavia, i valori del singolo byte e del byte di chiusura della sequenza potrebbero essere gli stessi. Ciò significa ad esempio che la ricerca carattere D (codice 44) può trovare erroneamente entrare nella seconda parte della sequenza di due byte carattere "D" (codice 84 44). Per determinare quale sequenza è corretta, il programma deve prendere in considerazione i byte precedenti.
La situazione diventa più complicata se il leader e il finalei byte corrisponderanno. Ciò significa che per invertire l'ambiguità, verrà eseguita una ricerca inversa fino all'inizio del testo o una sequenza di codice non ambigua. Questo non solo è inefficiente, ma non è protetto da possibili errori, perché un byte errato è sufficiente per rendere illeggibile l'intero testo.
Il formato di conversione Unicode evitadi questo problema, poiché i valori dell'unità di memorizzazione delle informazioni iniziale, di chiusura e singola non corrispondono. Per questo motivo, tutte le codifiche Unicode sono adatte per la ricerca e il confronto, non dando mai risultati errati a causa della coincidenza di diverse parti del codice carattere. Il fatto che queste forme di codifica osservino il principio di non assegnazione distingue da altre codifiche multibyte dell'Asia orientale.
Un altro aspetto della non intersezione delle codifiche Unicodeè che ogni personaggio ha confini chiaramente definiti. Ciò elimina la necessità di scansionare un numero indeterminato di caratteri precedenti. Questa caratteristica delle codifiche viene talvolta definita auto-sincronizzazione. La distorsione di una unità di codice porterà alla distorsione di un solo carattere e i caratteri circostanti rimarranno intatti. Nel formato di conversione a 8 bit, se il puntatore si riferisce a un byte che inizia con 10xxxxxx (nella codifica binaria), sono necessarie da una a tre transizioni inverse per trovare l'inizio del carattere.

coerenza
Unicode Consortium supporta pienamente tutti3 forme di codifica. È importante non opporsi a utf-8 e Unicode, perché tutti i formati di conversione sono ugualmente legittimi implementazioni di moduli di codifica dei caratteri Unicode.
Byte-orientamento
Per rappresentare il simbolo UTF-32, è necessaria un'unità di codice a 32 bit che corrisponde al codice Unicode. UTF-16: da una a due unità a 16 bit. E utf-8 usa fino a 4 byte.
La codifica utf-8 è stata creata per compatibilità consistemi orientati ai byte basati su ASCII. La maggior parte delle pratiche esistenti di software e informatica sono da tempo basate sulla rappresentazione di simboli sotto forma di una sequenza di byte. Molti protocolli dipendono dalla codifica ASCII non modificata e utilizza o evita caratteri di controllo speciali. Un modo semplice per adattare Unicode a tali situazioni è utilizzando la codifica a 8 bit per rappresentare caratteri Unicode equivalenti a qualsiasi carattere ASCII o carattere di controllo. Per questo, è prevista la codifica utf-8.
Lunghezza variabile
utf-8 è una codifica a lunghezza variabile composta daUnità di memorizzazione delle informazioni a 8 bit i cui bit di ordine elevato indicano a quale parte della sequenza appartiene ogni singolo byte. Un intervallo di valori è assegnato per il primo elemento della sequenza di codice, l'altro per gli elementi successivi. Questo garantisce una codifica disgiunta.

ASCII
la codifica utf-8 supporta pienamente i codici ASCII(0x00-0x7F). Ciò significa che i caratteri Unicode U + 0000-U + 007F vengono convertiti in un singolo byte 0x00-0x7F utf-8 e quindi diventano indistinguibili da ASCII. Inoltre, per evitare ambiguità, i valori 0x00-0x7F non vengono più utilizzati in alcun byte della rappresentazione di carattere Unicode. Per codificare simboli non ideografici diversi da ASCII, viene utilizzata una sequenza di due byte. I simboli dell'intervallo U + 0800-U + FFFF sono rappresentati da tre byte e quelli aggiuntivi con codici superiori a U + FFFF richiedono quattro byte.
Ambito di applicazione
La codifica utf-8 è solitamente preferita nel protocollo HTML e simile ad essa.
XML è diventato il primo standard con pieno supportocodifiche utf-8. Anche le organizzazioni coinvolte nella standardizzazione lo raccomandano. Il problema del supporto negli indirizzi URL diversi dai caratteri ASCII è stato risolto quando il consorzio W3C e il gruppo di tecnici IETF hanno accettato di codificare tutti gli URL esclusivamente in utf-8.
La compatibilità con ASCII facilita la transizione verso un nuovosoftware. Con utf-8 la maggior parte degli editor di testi funziona, inclusi JEdit, Emacs, BBEdit, Eclipse e Blocco note del sistema operativo Windows. Nessuna altra forma di codifica Unicode può vantare tale supporto dagli strumenti.
Il vantaggio della codifica è questoconsiste in una sequenza di byte. Con le stringhe utf-8, è facile lavorare in C e in altri linguaggi di programmazione. Questa è l'unica forma di codifica che non richiede la marcatura dell'ordine dei byte BOM o della dichiarazione di codifica in XML.

auto-sincronizzazione
In un ambiente che utilizza l'elaborazione di caratteri a 8 bit, rispetto ad altre codifiche multibyte, utf-8 presenta i seguenti vantaggi:
- Il primo byte della sequenza di codice contiene informazioni sulla sua lunghezza. Ciò aumenta l'efficienza della ricerca diretta.
- È più facile trovare l'inizio del carattere, poiché il byte iniziale è limitato a un intervallo di valori fisso.
- Non c'è intersezione di valori di byte.
Confronto dei vantaggi
la codifica utf-8 è compatta. Ma quando si applica la codifica dei caratteri dell'Asia orientale (cinese, giapponese, coreano, usando caratteri cinesi) vengono utilizzate sequenze a 3 byte. Anche la codifica utf-8 è inferiore ad altre forme di codifica per velocità di elaborazione. Un ordinamento di stringa binaria produce lo stesso risultato di un ordinamento binario Unicode.
Schema di codifica dei caratteri
Lo schema di codifica dei caratteri consiste in una formacodifica dei caratteri e un metodo di disposizione byte per pixel di unità di codice. Per determinare lo schema di codifica con lo standard Unicode, viene fornito l'uso del contrassegno di ordine byte iniziale (distinta base, contrassegno dell'ordine byte).
Quando BOM è abilitato in utf-8, la funzione labelè limitato solo dall'indicazione dell'uso del modulo di codifica. Non ci sono problemi nel determinare l'ordine dei byte in utf-8, poiché la sua dimensione dell'unità di codifica è di un byte. L'uso di BOM per questo modulo di codifica non è né obbligatorio né raccomandato. La distinta materiali può essere presente nei testi convertiti da altre codifiche che utilizzano il contrassegno di ordine dei byte o per la firma di codifica utf-8. È una sequenza di 3 byte di EF16 BB16 BF16.
Come impostare la codifica utf-8
In HTML, la codifica utf-8 è impostata usando il seguente codice:
testa
˂meta http-equiv = "Content-Type" content = "text / html; charset = utf-8" ˂
In PHP, la codifica utf-8 viene specificata utilizzando la funzione header () all'inizio del file dopo aver impostato il valore del livello di output dell'errore:
˂? Php
error_reporting (-1);
intestazione ("Content-Type: text / html; charset = utf-8");
Per connettersi ai database MySQL, la codifica utf-8 è impostata come segue:
˂? Php
mysql_set_charset ("utf8");
Nei file CSS, la codifica dei caratteri utf-8 è specificata come segue:
@charset "utf-8";

Quando si salvano file di tutti i tipi, selezionarecodifica utf-8 senza BOM, altrimenti il sito non funzionerà. Per fare ciò, nel programma DreamWeave, è necessario selezionare la voce di menu "Modifiche - Proprietà pagina - Titolo / Codifica", cambiare la codifica in utf-8. Quindi è necessario ricaricare la pagina, deselezionare la casella "Connetti firme Unicode (BOM)" e applicare le modifiche. Se un testo nella pagina o nel database è stato inserito da un altro modulo di codifica, deve essere reinserito o ricodificato. Quando si lavora con espressioni regolari, è obbligatorio utilizzare il modificatore u.
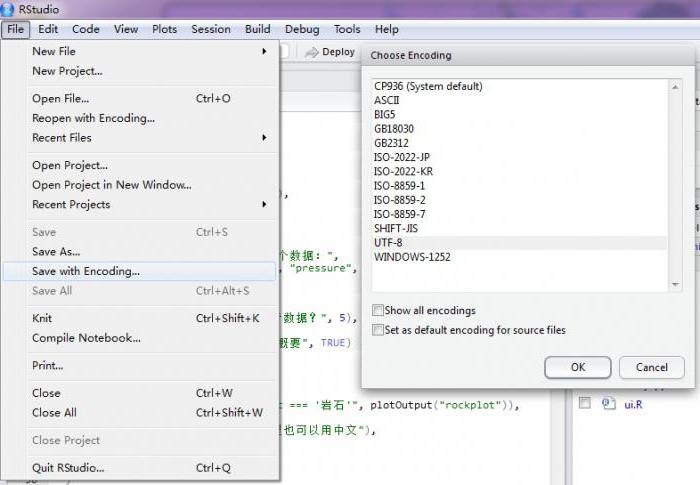
Puoi anche salvare il file nella codifica utf-8 nel Blocco note di Windows. Dopo aver selezionato la voce di menu "File - Salva come ...", imposta il modulo di codifica necessario e salva il file nella codifica utf-8.
Nell'editor di testo Notepad ++, se la codifica è diversa da utf-8, cambia la codifica e salvala nella codifica utf-8 tramite la voce di menu "Converti in utf-8 senza BOM".

Non c'è alternativa
Nel contesto della globalizzazione, quando politico ei confini della lingua vengono cancellati, insiemi di simboli che hanno caratteristiche locali meno utili. Unicode è l'unico set di caratteri che supporta tutte le localizzazioni. E utf-8 è un esempio dell'implementazione corretta di Unicode, che:
- supporta un'ampia gamma di strumenti, inclusa la compatibilità con la codifica ASCII;
- è resistente alla corruzione dei dati;
- semplice ed efficace nell'elaborazione;
- non dipende dalla piattaforma.
Con l'avvento della discussione utf-8 su quale forma di codifica o set di caratteri è meglio, sono diventati privi di significato.